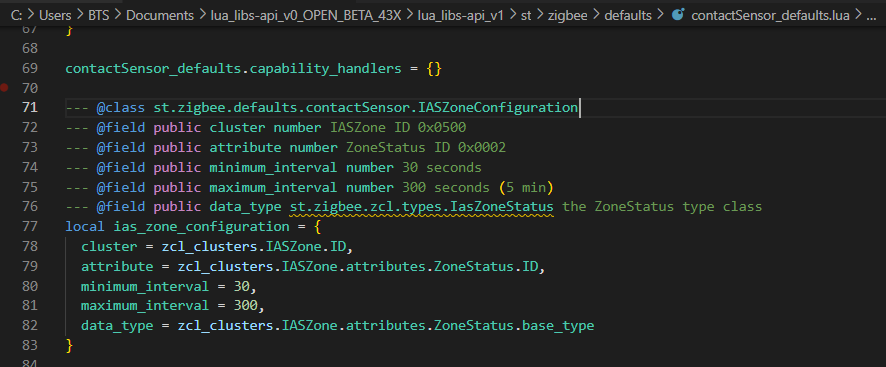
It looks like the default settings for when registering/configuring a IASZone device gets an IASZone/ZoneStatus (0x0002) reporting set to every 5 minutes max (with a 30 second minimum).
I see a mention here that this is by design and is used for tracking connected status/timeout of the device.
On old DTH’s when registering IAS devices there was no automatic reporting setup, so this is a change.
Are theses defaults overridable? Having a battery powered device sending a full report every 5 minutes seems excessive and will use quite a bit of battery. Every hour to every few hours seems more reasonable depending on the circumstances.
3 Likes
RBoy
(www.rboyapps.com - Making SmartThings Easy!)
2
Yes you can always override it. Depending on how you want, you can rebind or don’t use the default capability during registering the driver and instead handle it yourself during configuration or init.
If you want a different interval configured, you need to define a custom lifecycle for doConfigure. This will override the default config process and will send to the device the commands defined there instead.
It is important to send first a bind_request and then, the configure_reporting command. For example, this is a request to change this config for the IlluminanceMeasurement cluster:
local device_management = require "st.zigbee.device_management"
local zcl_clusters = require "st.zigbee.zcl.clusters"
local function do_Configure(self,device)
device:send(device_management.build_bind_request(device, zcl_clusters.IlluminanceMeasurement.ID, self.environment_info.hub_zigbee_eui))
device:send(zcl_clusters.IlluminanceMeasurement.attributes.MeasuredValue:configure_reporting(device, 60, maxTime, changeRep))
--It calls the configuration of the default handlers.
--So, register only to those you'll use
device:configure()
end
Haven’t you already been getting multiple reports about very short battery life with smartthings-created edge drivers?
If you’re requesting a report every five minutes, that’s going to kill battery life on your typical Zigbee sensor. The industry standard is once per hour, and that’s what most of those devices are spec’d to to get to their desired one to two year battery life.
If you’re forcing them to report 12 times more often you’re likely to see batterylife drop to one to two months.
This is when using an IAS device. Behind the scenes the framework is configuring the reporting on the IASZone cluster, attribute 0x0002. I’m not configuring any reporting myself for IASZone/ZoneStatus. 2022-08-18T17:48:17.352910645+00:00 INFO Zigbee Sensor <ZigbeeDevice: 724f7205-57a0-45e3-8b1b-0e235baadf1d [0xADD3] (Zigbee Sensor)> sending Zigbee message: < ZigbeeMessageTx || Uint16: 0x0000, < AddressHeader || src_addr: 0x0000, src_endpoint: 0x01, dest_addr: 0xADD3, dest_endpoint: 0x01, profile: 0x0104, cluster: IASZone >, < ZCLMessageBody || < ZCLHeader || frame_ctrl: 0x00, seqno: 0x00, ZCLCommandId: 0x06 >, < ConfigureReporting || < AttributeReportingConfiguration || direction: 0x00, attr_id: 0x0002, DataType: Bitmap16, minimum_reporting_interval: 0x001E, maximum_reporting_interval: 0x012C > > > >
None of this is documented for the default IAS zone registration, its different than it was under Groovy DTH’s, and seems excessive for battery powered devices. My test device is sometimes returning a Zone Status update every 30 seconds (even with no change, likely a bug in the device but its still doing it…).
I’ll look into what it would take to do IAS Zone registration and the other actions myself in my own do_configure().
Are the files with the default values available for us to download? I looked thru Github and the documentation but I can’t find a lua SDK or framework that might include those.
We already mentioned that to the internal team, but we haven’t received any feedback yet.
I was just answering from the driver development perspective.
For future reference, its under “Releases” in the SmartThingsCommunity/SmartThingsEdgeDrivers repo. I never can find “Releases” because its not a top level tab on the github repo view…
Some progress on how I approached implementation of the driver for this device (Linkind Leak Sensor):
The default IASZone/ZoneStatus attribute reporting time was indeed set in the leakSensor defaults. Again, I feel like 30sec min/300 second max reporting is far too often for a good battery life, but I just want to disable the reporting all together as its not needed (see next point). My solution was to remove the attribute from both the configured and monitored list inside of my init lifecycle routine: device:remove_configured_attribute(IASZone.ID, IASZone.attributes.ZoneStatus.ID) device:remove_monitored_attribute(IASZone.ID, IASZone.attributes.ZoneStatus.ID)
Then when the device is configured by the default handlers, no reporting is requested on that cluster/attribute. Standard IAS Zone registration runs as normal and works fine.
This device returns ZoneStatus in its IAS Zone registration with bit 4 set, meaning that it will “periodically” send a Supervision report (as a IASZoneStatusChangeNotification) with the current ZoneStatus for Edge to use as its “healthy” status. The period is about 120 minutes (2 hours), which seems about right to me. So the refresh of the attribute above isn’t needed as its going to do these supervision reports anyway.
I’m testing the driver now and will let it run for the next few days to see how it fares but so far it looks clean.
Take aways:
I would like to see a way to override the behavior of setting the IAS ZoneStatus attribute report schedule via the device template. The other IAS parameters/handlers/behavior are all configurable but not the attribute reporting.
Perhaps the default logic could be smarter if a device supports Supervision reports (reported via bit 4 in ZoneStatus return from the IAS zone registration process). If its sending supervision reports, no need to also configure it for periodic IAS Zone/ZoneStatus attribute reporting.
30 second min/300 second max is far too aggressive for battery powered sensors IMO. The other device handlers that support IAS defaults were all set to these values too. I suspect there will be bunch of people saying their batteries are being chewed once more people are using Edge drivers.
You may be right, but I think thst stock DTHs also had that setting to defsult report every 300 sec, and I think remember, that in the live log of the IDE they were also seen reports every 300 sec
so for this reason you shouldn’t notice a change in battery life when switching to an edge driver
def configure() {
// Device-Watch allows 2 check-in misses from device + ping (plus 1 min lag time)
// enrolls with default periodic reporting until newer 5 min interval is confirmed
sendEvent(name: "checkInterval", value: 2 * 60 * 60 + 1 * 60, displayed: false, data: [protocol: "zigbee", hubHardwareId: device.hub.hardwareID, offlinePingable: "1"])
log.debug "Configuring Reporting
Device watch just ran ping() when it expired (your example was 2 hours plus 1 minute) which most battery powered devices just had as an empty function. All mine did for sure. Some devices have a long poll within the 7 second window so doing a refresh() type action within poll() makes sense. But a lot of devices fall well outside the long poll window to hear a query anyways.
DTH default handlers (for IAS registration) never setup a 300 second attribute reporting on the IASZone status by default either. The ST provided DTHs may have used ZoneStatus reporting on certain devices, but not likely sensors with tiny coin cell batteries, etc.
I am not an expert in this, but I think that what they have wanted to do when converting the stock DTH to driver edge is to make a functionality identical to DTH, therefore I think that if this is what the edge driver does, it is because the DTH towards the same or have made a mistake, maybe @nayelyz can found some clarification, In case it is an error, correct it in the custom drivers
By the way, I remembered that the default code to set offline or online the zigbee devices use that configured report interval of 5 minutes to calculate the healtChek.
Take a look at this report I made about dialing online, in case it helps you in case of disconnections
I saw that code too. However, I think it has slightly different behavior than what you’re describing.
That code appears to check any attribute result marked as needing monitored. Every 30 seconds a routine runs to check thru all the monitored attributes and if they have expired, it sends an Attribute Get and resets the timeout. It will retry this logic (wait for timeout, send an Attribute Get) forever, there is no max number of attempts. It does have some error recovery that if an Attribute Response returns with an ERROR, the attribute is removed from the monitor list so it doesn’t attempt it again.
The actual device “health” (seen in the CLI with device:status as “status”) of ONLINE or OFFLINE does not appear to be affected by the above logic directly. Ie, its not as if once it fails X times it marks the device as OFFLINE.
The documentation alludes to the ONLINE/OFFLINE state is monitored/set by the radios themselves, likely once they detect too many failed ACKs to a device. The attribute monitor logic above may help prime that pump (so that the Attribute Gets end up failing to send) but the two subsystems don’t appear to be directly connected.
So my take is there are several models all in play here.
DTH’s had DeviceCheck/HealthWatch which was more of a watchdog at the application level that would kick with ping(). ping() would try and contact the device and the resulting data received would kick the watchdog further, completing the loop. If DeviceCheck continued to timeout too far the device would be marked OFFLINE.
Edge appears to have a system where attributes can be monitored and if they expire (1.5x the max rate + random seed) they get queried. Then a separate system monitoring the radios view of the device for setting ONLINE/OFFLINE status.